.png)
Indexed RAG vs. Federated Search: Choosing the Right Architecture for Legal AI Document Retrieval
Legal and Enterprise AI systems retrieve information from company documents through two distinct technical architectures. The first, often called "federated access," queries your document management system directly whenever you search. The second, "indexed retrieval," creates a synchronized, searchable copy of your documents within the AI system's infrastructure. Both approaches work, but they perform very differently for legal work at scale.
This article explains the technical and practical differences between these architectures and examines the trade-offs that led casepal and other legal AI providers to choose indexed approaches.
The Architectural Choice: Indexed RAG vs Federated Access
Understanding the architectural difference is essential when evaluating AI providers or building internal solutions.
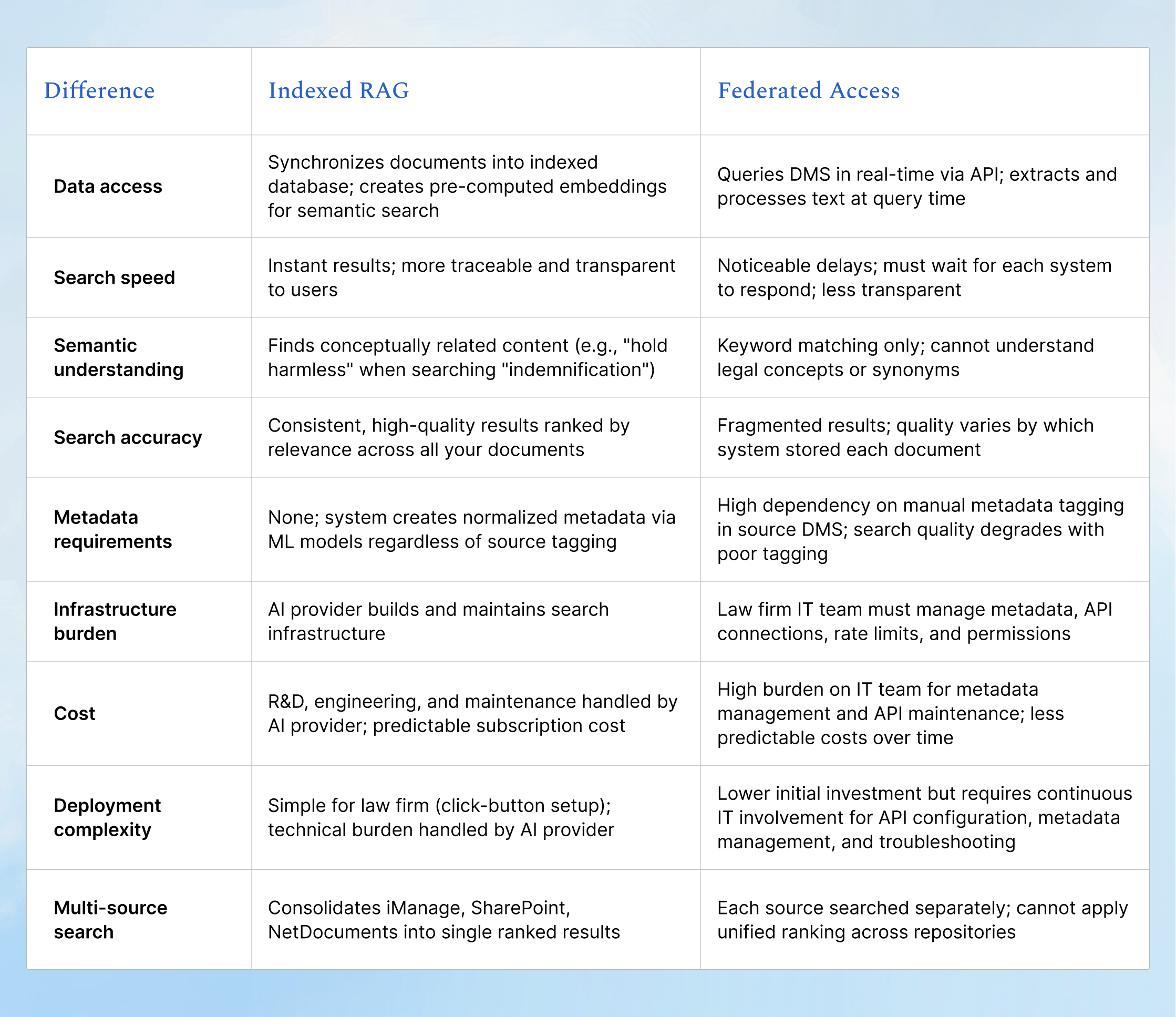
Federated Access: Querying the document management system in real-time whenever a search occurs. The AI calls your DMS API on demand, extracts relevant text, and processes it at query time. No pre-indexing required.
Indexed RAG (Retrieval-Augmented Generation): Synchronize documents into the AI system, create searchable embeddings, numerical representations that capture meaning, and query this indexed library. This requires initial setup but enables semantic search and sub-second retrieval.
On the surface, federated access sounds simpler: no synchronized copies, no indexing overhead, just direct API calls to your existing systems. When evaluating both approaches against the requirements of production legal work, the performance gap became decisive.
Speed and Performance: Why Pre-Computation Matters
Indexed search builds a pre-processed, centralized repository that delivers consistent, rankable results in milliseconds. When casepal synchronizes your library, every file is processed by an algorithm that converts documents into dense numerical vectors (embeddings) that capture the semantic meaning of the content. When you ask a question, the system performs a vector search across the library, finding the vectors most similar to your query and retrieving the most relevant information.
Federated search systems, by contrast, access the client's document management system directly. Since files are not processed beforehand, the system relies on metadata to identify potentially relevant files, and metadata must be added manually. This approach is outdated because metadata preserves only limited information and generally fails to capture the semantic meaning of documents.
This metadata dependency creates a performance bottleneck. Every time a federated search is executed, the system must complete three additional steps: (1) metadata lookup, (2) text extraction with OCR for scanned files, and (3) preprocessing for analysis. These steps can take anywhere from 2 seconds to 2 minutes for documents requiring OCR Processing. Indexed RAG, by contrast, performs retrieval from thousands of documents in under a second.
Case example
Consider a law firm implementing an internal search for a corpus of 10,000 documents.
With federated search:
You ask for a "summary of case XYZ." The tool directly accesses your database and looks for files with metadata matching "case XYZ." Once it finds files with matching metadata (assuming the metadata was tagged correctly), it extracts text from those files. Since some files are scanned, extracting content from all files with matching metadata may take several minutes. Lastly, since federated search cannot assess document content before extraction, it feeds all file content to the AI, including irrelevant sections. This quickly leads to context overflow (exceeding the AI's processing limits) and inaccurate results.
Time: 2 seconds to 2+ minutes
Result: Potentially inaccurate due to irrelevant content and metadata dependency
With indexed RAG (casepal):
You ask the same question: "summary of case XYZ." casepal uses the conversation context to create a query and queries the vector database. Within a second, it retrieves all relevant information about your case based on both keywords and semantic meaning, while filtering out irrelevant content.
Time: Under 1 second
Result: Precise, contextualized information with irrelevant content filtered out
At scale, this difference compounds. When searching across 100,000 documents with multiple concurrent users, a common scenario for a legal team, the gap between instant and slow determines whether professionals adopt the tool in their daily work or abandon it as too frustrating to use.
Semantic Search Requirement: Understanding of Legal Meaning
Indexed architecture is not only justified by its speed. One of the most decisive factors is semantic understanding, the ability to find conceptually related content, not just keyword matches.
Federated systems rely on each external source's own search capabilities and ranking algorithms. They lack a unified view of content across different repositories and, therefore, cannot apply consistent metadata and relevancy scoring algorithms to the content. As a result, the system is more likely to return fragmented and unhelpful information.
A lawyer searching for indemnification provisions needs to find "hold harmless agreements," "compensation for loss," and "liability protection," not just exact keyword matches. Semantic search enables this by understanding that similar concepts cluster together in vector space, allowing the system to find conceptually related content regardless of exact term overlap.
For example, semantic search finds firm precedents using "material adverse change" when searching for "MAC clauses," or locates opinions discussing "consequential damages exclusion" when searching for "indirect loss limitations," domain-specific contextual similarities that would be impractical to find manually across thousands of documents.
While semantic layers can technically be added to federated systems, achieving semantic search at production scale with sub-second performance requires pre-computed embeddings stored in indexed databases. Computing embeddings at query time creates prohibitive latency and cost, making it impractical for legal AI.
The Practical Cost: Who Bears the Burden?
The assumption that federated access is "simpler" and more cost-effective overlooks a critical question: simpler for whom?
Federated search relies entirely on the metadata and search capabilities of each source system. The quality of search results depends directly on how well documents are tagged, categorized, and indexed within the source repositories. This places the infrastructure burden squarely on the law firm or enterprise: your IT team must ensure every document across every repository has accurate, searchable metadata.
For a firm with 50,000+ documents, this isn't trivial. Federated search systems depend on metadata for filtering and categorization. If metadata is incomplete or inconsistent across repositories, search quality degrades significantly, as the system cannot compensate for poor tagging in the underlying sources.
Indexed retrieval inverts this burden. The AI provider, not your firm, builds the infrastructure for semantic understanding, relevance ranking, and unified search. Indexed systems create their own normalized metadata and apply machine learning models to understand content, regardless of how documents are organized in source systems. This shifts the technical complexity from the customer's IT team to the vendor's engineering team.
Beyond direct costs, operational complexity shifts. Federated systems require continuous API management to handle rate limits, maintain connections to multiple repositories, and synchronize permissions in real-time. Research shows these systems rely on APIs that are often slow, incomplete, or poorly maintained, as these APIs aren't optimized for search relevance but are often provided as a convenience, not a core product.
With indexed retrieval, your firm syncs documents once. The AI provider handles indexing, embedding generation, metadata normalization, OCR processing, and performance optimization. You get enterprise-grade search infrastructure without building or maintaining anything beyond your standard DMS.
Unified Retrieval Across Multiple Data Sources
Indexed architecture solves another challenge that federated systems cannot: unified search performance and speed across multiple document management systems and data sources.
With indexed retrieval, you can consolidate documents from iManage, SharePoint, NetDocuments, and internal file shares into a single searchable library. The system normalizes all content into a unified format and applies consistent relevance ranking, regardless of where documents originated.
Federated search, by contrast, remains constrained by each source system's individual ranking logic and search capabilities. If one DMS uses simple keyword matching while another offers basic relevance scoring, your results are fragmented, limited by the weakest system in the chain.
This "lowest common denominator" problem means federated systems cannot apply sophisticated machine learning models for relevance ranking across heterogeneous sources. Each repository is searched separately, and merging results into a coherent, ranked list becomes impossible. While federated systems can aggregate results, they must use simplistic ordering rules (by date, alphabetically, or round-robin) rather than unified relevance scoring.
Synthesizing External Law and Internal Knowledge in One Analysis
This unified indexed architecture enables capabilities beyond what is possible with federated access.
casepal's Agentic Legal Research, for example, simultaneously searches external legal authorities (legislation and case law from 60+ jurisdictions) and your internal institutional knowledge (templates, precedents, past submissions) in a single analysis. When you ask a legal question in natural language, casepal retrieves, analyzes, and synthesizes relevant content from both external databases and your firm's SharePoint repositories, grounding every assertion with verifiable citations to primary sources, secondary authorities, or internal precedents. This synthesis of external law and internal expertise, delivered in one unified response with OSCOLA-compliant citations, is possible as internal files are indexed in a unified, searchable format.
With casepal Library, a lawyer searching for force majeure precedents gets unified results across all relevant data sources, internal and external, ranked by semantic relevance, not by which DMS happened to store each document.
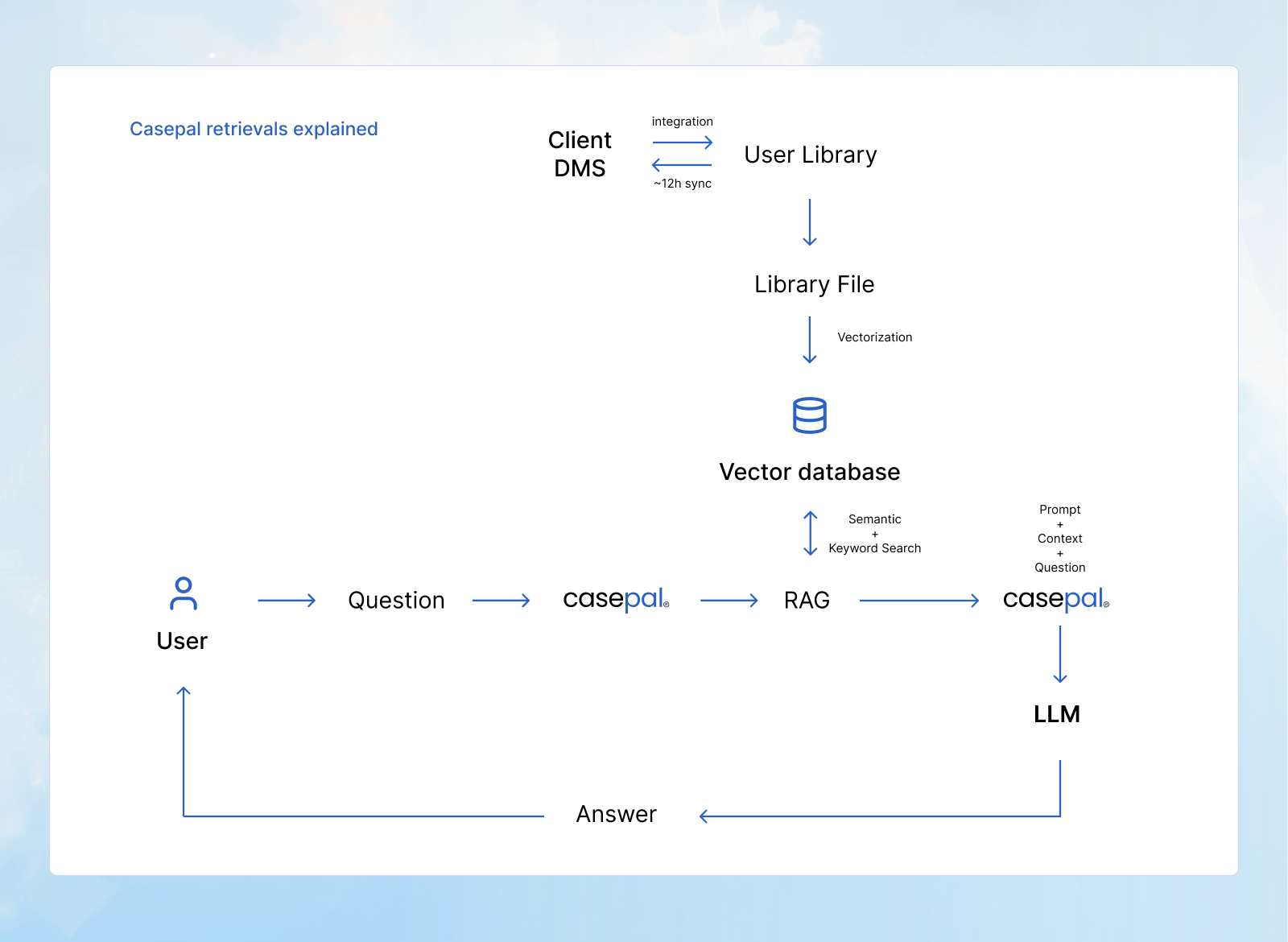
How casepal Library Implements Indexed RAG
casepal Library uses a hybrid retrieval architecture that combines domain-specific semantic understanding with keyword precision to deliver accurate, contextual results for legal queries.
Document Import and Synchronization
Documents from your systems, such as SharePoint, or direct uploads, are synchronized into casepal Library through automated connectors. This synchronization runs automatically in real-time, detecting new documents, updates, and deletions without manual intervention.
The system supports a comprehensive range of file formats, including pdf, docx, doc, oft, txt, xlsx, xls, csv, pptx, ppt, eml, and png files, with OCR processing applied to scanned documents and images to extract searchable text.
During import, each document is processed through multiple stages:
OCR processing: Scanned PDFs and image files are processed with optical character recognition to extract searchable text from non-machine-readable documents
Text extraction: Content is extracted while preserving document structure and metadata
Chunking: Documents are segmented into semantically meaningful sections to enable precise retrieval
Embedding generation: Each chunk is converted into domain-specific legal embeddings, numerical vectors that capture the semantic meaning of legal concepts
Indexing: Both vector embeddings (for semantic search) and traditional keyword indexes (for exact matching) are created and stored in your Library
Agentic Source Selection and Retrieval
When you submit a query to casepal, the system first analyzes your question to determine which data sources are relevant to your request.
Step 1: Intelligent Source Selection
casepal's agentic layer evaluates your query intent and automatically decides whether to search:
- External legal authorities: Legislation and case law databases across 60+ jurisdictions
- Internal Library: Your firm's documents, templates, precedents, and institutional knowledge
- Both sources: For queries requiring synthesis of external law and internal expertise
A question about "GDPR Article 17 requirements" triggers an external legal database search. A request for "our standard force majeure clause in construction contracts" searches your Library. A query like "draft a data processing agreement compliant with GDPR using our standard clauses" searches both—retrieving relevant GDPR provisions from external sources and your firm's DPA templates from the Library.
Step 2: Dual Retrieval Strategy
Once the relevant data sources are identified, casepal executes two parallel search strategies against those sources:
Semantic Search: State-of-the-art domain-specific legal embeddings trained on legal corpora understand relationships between legal concepts. This enables the system to find "indemnification" clauses written as "hold harmless agreements" or locate "material adverse change" provisions when searching for "MAC clauses." The semantic layer understands legal terminology, jurisdictional variations, and conceptual relationships that keyword matching alone would miss.
BM25 Keyword Matching: A probabilistic ranking function that excels at exact term identification, critical for case citations, statute references, article numbers, and specific legal terminology. When you search for "Article 5(2)(b) GDPR" or "Smith v Jones [2023] UKSC 15," BM25 ensures precise matches.
Step 3: Iterative Research Protocols
Following legal research methodology, casepal's Agentic Legal Research executes a structured, iterative process when queries require comprehensive analysis:
Find relevant sources: The system conducts initial searches across selected data sources, whether external legal databases, your Library, or both, looking for applicable statutes, case law, firm precedents, and authoritative materials.
Analyze and evaluate: casepal reviews whether the relevant sources have been found and determines whether additional research is needed to effectively answer the legal question. The system assesses gaps in coverage, evaluates source quality, and identifies areas requiring deeper investigation.
Continue searching if necessary: If initial retrieval is insufficient, casepal performs additional targeted searches—refining queries, exploring specific subsections of the data sources, or pivoting to alternative search strategies—until it has gathered sufficient high-quality sources for a comprehensive response.
This iterative approach can focus on a specific data source (conducting multiple rounds of searches within your Library to find the most relevant precedents) or span multiple sources (first retrieving primary legal authorities externally, then searching your Library for how your firm has applied those authorities in past matters).
Step 4: Result Fusion and Synthesis
Results from both retrieval methods are merged using Reciprocal Rank Fusion, a ranking algorithm that prioritizes documents that score highly on both semantic similarity and keyword relevance. When external and internal sources are both searched, results are synthesized into a unified response, ensuring you receive answers that are both conceptually relevant and terminologically precise, grounded in the appropriate combination of legal authorities and institutional knowledge. Every assertion is supported by verifiable citations, distinguishing between external legal sources and internal firm materials.

SharePoint Integration
Integration with Microsoft SharePoint operates via the MCP (Model Context Protocol) framework, a standardized approach for connecting AI systems with enterprise data sources. The integration:
- Respects your existing folder structures and organizational hierarchies
- Syncs incrementally, processing only changed content rather than re-indexing entire repositories
- Maintains metadata (authors, creation dates, document types, custom SharePoint fields) for filtering and context
Context Assembly and Generation
Retrieved document chunks are assembled into context and combined with your query. This context, containing the most relevant passages from your indexed documents and, when relevant, external legal sources, is sent to the large language model, which generates a response grounded in actual source material. Every assertion references its source through verifiable citations, distinguishing between external legal authorities and internal institutional knowledge.
The result: Instant retrieval across thousands of documents, finding conceptually similar content that keyword search would miss, while maintaining precision for exact legal terms, all with zero ongoing maintenance for the legal team after initial setup.
Why Document Synchronization Actually Reduces Maintenance
Indexed retrieval requires document synchronization to create a searchable copy of your files within the AI system's infrastructure. This one-time setup actually reduces your ongoing maintenance burden compared to federated systems.
The synchronization is fully automated. After initial setup, the system handles change detection, incremental updates, and re-indexing automatically, monitoring your source repositories for updates, deletions, and new documents, then processing only what changed.
Critically, indexed systems eliminate the metadata management burden that federated systems impose. Federated search depends entirely on how well documents are tagged and categorized in your source systems. Poor or inconsistent metadata degrades search quality. With indexed retrieval, the AI provider creates normalized metadata through machine learning models, regardless of how documents are organized in your DMS. You get high-quality semantic search without manual tagging, metadata schemas, or ongoing optimization.
The result: zero ongoing maintenance, no metadata management requirements, and enterprise-grade search infrastructure that works regardless of how your documents are currently organized.
How Production Legal AI Systems Are Built
Major legal AI platforms built for enterprise use, such as Harvey Vault, Legora's Tabular Review casepal Library, and beyond, use indexed retrieval architecture, as it is the only approach that delivers the performance and semantic accuracy that legal work requires.
The pattern is universal: the AI provider builds and maintains the search infrastructure, and the law firm uses it.
This division of responsibility is deliberate. Building semantic search systems requires specialized engineering, vector databases, embedding models, relevance ranking algorithms, permission controls, and continuous performance optimization. Law firms shouldn't have to build this infrastructure themselves. They should receive it as a managed service from their domain-specific AI provider.
When you use casepal Library, Harvey Vault, or any production legal AI system, the provider handles:
- Document indexing and embedding generation
- OCR-processing
- Semantic search infrastructure
- Performance optimization at scale
- Automatic synchronization of updates
The law firm or in-house team provides knowledge and expertise through their documents. The AI provider delivers the architecture and application that allows organization-specific searchable intelligence.
Federated systems, by contrast, shift the infrastructure burden back to the law firm/enterprise, requiring metadata management, API maintenance, and performance troubleshooting across multiple repositories.
Key Takeways
Indexed retrieval architecture delivers capabilities that federated systems cannot:
Speed at scale – Instant retrieval that feels immediate to users, even across hundreds of thousands of documents with concurrent users. Federated systems introduce noticeable delays, making them impractical for daily workflows.
Semantic Understanding for Legal – Finding "hold harmless agreements" when searching for indemnification, or "material adverse change" when searching for "MAC clauses." Discovers relevant precedents that would require manually reviewing thousands of documents.
Unified multi-source search – Consolidates different DMS, such as SharePoint, into one searchable Library. Enables casepal's Agentic Legal Research to simultaneously search external legal authorities and internal firm knowledge, synthesizing both into unified, cited responses.
Zero metadata burden – Automatically extracts and normalizes metadata from documents, regardless of how they're organized in source systems. Federated search depends on manual tagging in your DMS; poor tagging degrades search quality.
Zero ongoing maintenance – Automated synchronization handles updates without IT involvement. Federated systems require continuous API management and troubleshooting.
Predictable costs – AI provider handles all infrastructure investment. Law firms get predictable subscription costs, not variable API fees and unpredictable IT service fees for metadata management.
Law firms should not build this infrastructure themselves. With indexed retrieval, the AI provider handles engineering complexity; the law firm uploads documents and receives state-of-the-art searchable intelligence with zero ongoing IT maintenance.
This is the industry best-practice that casepal Library is built upon, the architecture that is delivering instant speed, semantic accuracy, multi-source unification, including external authorities, and a fully managed infrastructure.